

/cdn.vox-cdn.com/uploads/chorus_asset/file/23951502/VRG_Illo_STK172_L_Normand_JackDorsey_Neutral.jpg)



Nvidia H100 meurt.
Cette semaine, Nvidia a publié un document de recherche décrivant comment l’IA générative peut être utilisée dans la conception de semi-conducteurs. Le scientifique en chef de Nvidia, Bill Daly, a annoncé le nouveau document lors de son discours d’ouverture à la Conférence internationale sur la conception assistée par ordinateur (Icad) se déroule actuellement à San Francisco.
« Cet effort représente une première étape importante dans l’application des diplômes LLM au travail complexe de conception de semi-conducteurs », a déclaré Daly lors de l’événement à San Francisco. « Cela montre comment même des domaines hautement spécialisés peuvent utiliser leurs données internes pour former des modèles d’IA génératifs utiles. »
« Je pense qu’avec le temps, les grands modèles de langage seront utiles dans tous les processus, dans tous les domaines », a déclaré Mark Renn, directeur de recherche chez Nvidia et auteur principal de l’article. Nvidia a publié un Blog Travailler ensemble avec papier (ChipNeMo : MBA adapté au domaine pour la conception de puces).
La conception des puces géantes d’aujourd’hui, comme le GPU H100 de Nvidia, nécessite généralement deux ans d’efforts impliquant plusieurs équipes d’ingénierie. L’émergence soudaine des domaines du LLM et de l’intelligence artificielle générative a déclenché une vague d’efforts pour développer des cours LLM personnalisés et spécifiques à un domaine. Bloomberg Finance LLM (GPT Bloomberg) est un bon exemple.
Les LLMS spécifiques à un domaine devraient rejoindre le monde des outils EDA et accéléreront et amélioreront considérablement la conception de puces complexes. À ce stade, ChipNeMo est un projet interne destiné à un usage interne uniquement. Le résumé de l’article résume bien le travail :
Résumé : « ChipNeMo vise à explorer les applications des grands modèles de langage (LLM) à la conception de puces industrielles. Au lieu de déployer directement des LLM commerciaux ou open source prêts à l’emploi, nous adoptons plutôt les techniques d’adaptation de domaine suivantes : tokenisation personnalisée, domaine continu pré-formation Adaptive, Supervised Fine-tuning (SFT) avec des instructions spécifiques au domaine et des modèles de récupération adaptés au domaine.
« Nous évaluons ces méthodes sur trois applications LLM sélectionnées pour la conception de puces : un assistant d’ingénierie, la génération de scripts EDA et la synthèse et l’analyse des défauts. Nos résultats montrent que ces techniques d’adaptation de domaine permettent des améliorations significatives des performances LLM par rapport aux modèles de base à usage général dans trois domaines. applications évaluées. » , permettant une réduction jusqu’à 5 fois de la taille du modèle avec des performances similaires ou meilleures sur une gamme de tâches de conception. Nos résultats indiquent également qu’il y a encore place à l’amélioration entre nos résultats actuels et les résultats idéaux. Nous pensons que d’autres recherches dans des applications adaptatives. Les méthodes de terrain et LLM aideront à combler cet écart à l’avenir.
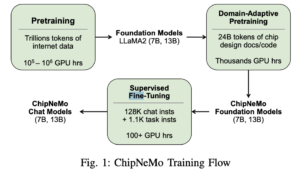 « Nous pensons que le MBA a le potentiel d’améliorer la productivité de la conception de puces en utilisant l’IA générative pour automatiser de nombreuses tâches de conception de puces liées au langage, telles que la génération de code, les réponses aux questions d’ingénierie via une interface en langage naturel, l’analyse et la génération de rapports », les auteurs de la recherche. a écrit. Erreurs.
« Nous pensons que le MBA a le potentiel d’améliorer la productivité de la conception de puces en utilisant l’IA générative pour automatiser de nombreuses tâches de conception de puces liées au langage, telles que la génération de code, les réponses aux questions d’ingénierie via une interface en langage naturel, l’analyse et la génération de rapports », les auteurs de la recherche. a écrit. Erreurs.
Nvidia a sans aucun doute un intérêt personnel ici, à la fois en renforçant sa position dans la communauté des développeurs/fournisseurs LLM et en générant une demande pour sa large gamme de produits. ChipNeMo est construit avec Nvidia Némo Framework cloud pour le développement et la formation LLM.
Avant de démarrer le projet ChipNeMo, Nvidia a mené une enquête sur les applications potentielles du LLM au sein de ses équipes de conception. Selon le document, les réponses se répartissaient grossièrement en quatre groupes : génération de code, questions et réponses, analyse et reporting, et triage.
« La génération de code fait référence au code de conception qui crée le LLM, les bancs de test, les assertions, les scripts d’outils internes, etc. ; les questions et réponses font référence au LLM qui répond aux questions sur les conceptions, les outils, les infrastructures, etc. ; l’analyse et le reporting font référence au LLM qui analyse les données et fournit des rapports ; Le tri fait référence à un LLM qui aide à corriger les erreurs de conception ou les problèmes d’outils à la lumière des journaux et des rapports. Nous avons choisi une application majeure de chaque catégorie à étudier dans ce travail, à l’exception de la catégorie Tri que nous partir pour des recherches plus approfondies.
Le document discute de la stratégie et des mesures prises pour développer ChipNeMo, fournissant un modèle approximatif pour d’autres. De toute évidence, d’autres tâches peuvent être accomplies. Le blog de Nvidia a rapporté qu’il avait d’autres projets pour concevoir des semi-conducteurs utilisant l’intelligence artificielle Concevoir des circuits plus petits et plus rapides Et pour Placement amélioré des gros blocs.
Nvidia a déclaré qu’une leçon importante tirée du projet ChipNeMo est que les programmes LLM spécifiques à un domaine peuvent être assez petits et fonctionner efficacement sur des plates-formes informatiques plus petites.
Ceci vient du marais : « Dans les tâches de conception de puces, les modèles ChipNeMo personnalisés avec au moins 13 milliards de paramètres correspondent ou dépassent les performances de cycles LLM à usage général beaucoup plus grands tels que LLaMA2 avec 70 milliards de paramètres. Dans certains cas d’utilisation, les modèles ChipNeMo étaient meilleurs En cours de route, a ajouté Ren, les utilisateurs doivent faire attention aux données qu’ils collectent et à la manière dont ils les nettoient pour les utiliser dans la formation.
lien du blog, https://blogs.nvidia.com/blog/2023/10/30/llm-semiconductors-chip-nemo/
lien papier, https://d1qx31qr3h6wln.cloudfront.net/publications/ChipNeMo%20%2824%29.pdf
à propos de

« Évangéliste amateur de zombies. Créateur incurable. Fier pionnier de Twitter. Amateur de nourriture. Internetaholic. Introverti hardcore. »
More Stories
Bluesky confirme que Jack Dorsey n’est plus membre de son conseil d’administration
Les plus grandes mises à niveau de l’IA d’iOS 18 sont présentées dans un nouveau rapport complet
Akuma de Tokido : premières impressions du jeu Après avoir essayé le prochain DLC de Street Fighter 6 en avance, je ne sais pas si le démon est tout-puissant