





Le développement de grands modèles de langage multimodaux (MLLM) représente une transformation révolutionnaire dans le domaine en évolution rapide de l’intelligence artificielle. Ces modèles avancés, qui combinent les puissantes capacités des grands modèles de langage (LLM) avec des entrées sensorielles améliorées telles que les données visuelles, redéfinissent les limites de l'apprentissage automatique et de l'intelligence artificielle. L'intérêt accru pour la gestion MLM, illustré par le GPT-4V d'OpenAI, souligne une tendance significative dans le monde universitaire et l'industrie. Ces modèles ne visent pas seulement à traiter d’énormes quantités de texte, mais également à créer une compréhension plus complète en combinant des données textuelles avec des informations visuelles. Un nouveau document de recherche du Tencent Youtu Lab, du Shanghai AI Lab, du CUHK MMLab, de l'USTC, de l'Université de Pékin et de l'ECNU propose une exploration approfondie du nouveau MLLM de Google, Gemini, qui émerge comme un concurrent potentiel du leader actuel dans le domaine. . GPT-4V. L'étude examine attentivement les capacités des Gémeaux en matière d'expérience visuelle et de pensée multimodale, ouvrant la voie à une évaluation complète de leur position dans le paysage en évolution rapide des MLLM.
Le GPT-4V d'OpenAI est actuellement une référence en matière de MLLM, présentant des capacités multimédia impressionnantes selon différentes normes. Cependant, la version Gemini de Google représente une nouvelle dynamique. Cet article compare les capacités de Gemini avec GPT-4V et Sphinx, un modèle MLLM open source de pointe. La comparaison vise à illustrer les différences de performances entre les systèmes open source et fermés dans le domaine MLLM.
Gemini, le nouveau MLLM de Google, a été exploré pour son efficacité en matière de compréhension visuelle. Les chercheurs ont examiné Gemini Pro, qui couvre plusieurs domaines tels que la perception de base, la perception avancée et les tâches de niveau expert. Cette approche teste les limites de Gemini et fournit une analyse approfondie des capacités de compréhension multimodale.
La méthodologie adoptée pour évaluer Gemini implique une plongée profonde dans différentes dimensions de la compréhension visuelle. Ceux-ci incluent la perception basée sur les objets, la compréhension au niveau de la scène, l'application des connaissances, la perception avancée et la gestion de tâches visuelles difficiles. Les performances de Gemini sont soigneusement comparées à celles de GPT-4V et de Sphinx dans ces domaines, fournissant une compréhension précise de ses forces et de ses faiblesses.
Les Gémeaux démontrent un défi de taille par rapport au GPT-4V, l'égalant ou le surpassant dans de nombreux aspects du raisonnement visuel. Contrairement à la préférence de GPT-4V pour les explications détaillées, Gemini opte pour des réponses directes et concises, mettant en évidence les différences dans les styles de réponse. Malgré sa compétitivité, Sphinx n'atteint pas la généralisabilité de ses pairs. L'analyse quantitative confirme également l'impressionnante compréhension multimodale de Gemini, indiquant sa capacité à rivaliser avec GPT-4V sur la scène MLLM.

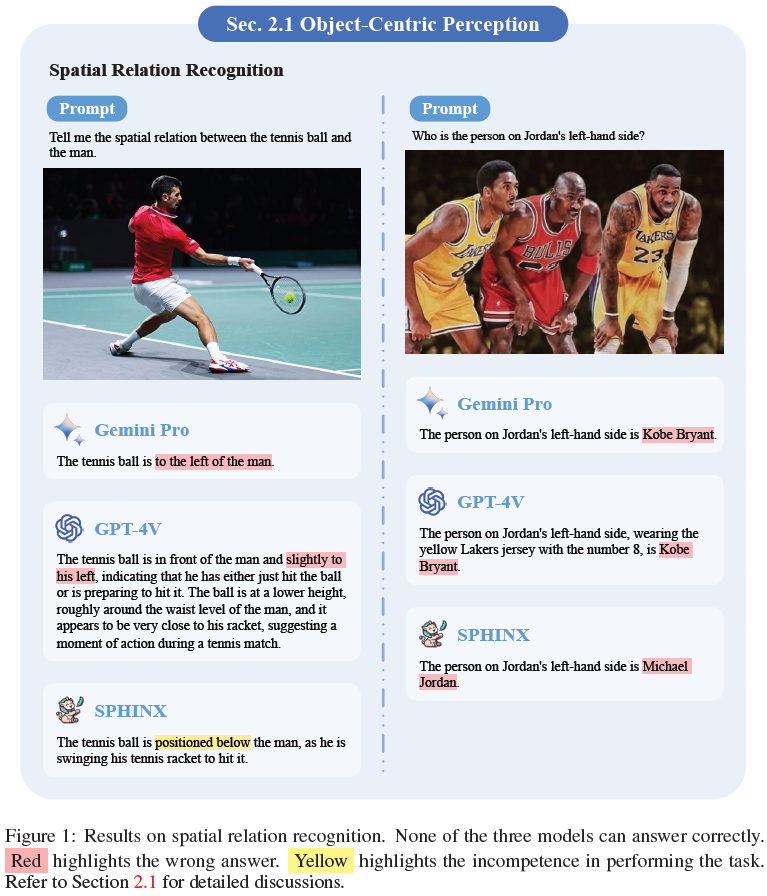
L'exploration de Gemini Pro révèle son grand potentiel en tant que concurrent de GPT-4V en matière d'apprentissage multimédia. Ce travail met en évidence les capacités actuelles de ces modèles avancés et révèle des défis communs, tels que la perception spatiale et les incohérences logiques. Ces résultats sont essentiels pour orienter les futures recherches et applications MLLM.
En conclusion, cette recherche fournit des informations précieuses sur le monde en évolution du MLLM. Gemini, avec sa puissance unique, ainsi que GPT-4V et Sphinx, repoussent collectivement les limites de la compréhension multimodale. Cette étude met en évidence les développements en cours dans ce domaine et les étapes vers la réalisation de formes d’intelligence artificielle plus inclusives.
Vérifier la papier. Tout le mérite de cette recherche revient aux chercheurs de ce projet. N'oubliez pas non plus de vous inscrire Nous avons plus de 35 000 ML SubReddit, 41 000+ communautés Facebook, Chaîne Discorde, Et Courrieloù nous partageons les dernières nouvelles en matière de recherche sur l'IA, des projets intéressants en matière d'IA et bien plus encore.
Si vous aimez notre travail, vous allez adorer notre newsletter.


Mohammad Athar Janaei, consultant stagiaire chez MarktechPost, est un partisan d'un apprentissage profond efficace, en mettant l'accent sur une formation clairsemée. Poursuivez une maîtrise. Il est titulaire d'un baccalauréat en génie électrique, spécialisé en génie logiciel, et allie connaissances techniques avancées et applications pratiques. Son projet actuel est sa thèse sur « l'amélioration de l'efficacité de l'apprentissage par renforcement profond », qui démontre son engagement à améliorer les capacités de l'intelligence artificielle. Le travail d'Athar se situe à l'intersection entre la « formation DNN clairsemée » et « l'apprentissage par renforcement profond ».

« Évangéliste amateur de zombies. Créateur incurable. Fier pionnier de Twitter. Amateur de nourriture. Internetaholic. Introverti hardcore. »
More Stories
Rabbit nie les allégations selon lesquelles son assistant virtuel R1 serait une application Android glorifiée
AWS propose la carte météo en ligne CloudWatch
FAST Hub Samsung TV Plus ajoute des programmes sportifs, familiaux et d'information, et innove avec la diffusion en direct des matchs des LA Kings AHL d'Ontario Reign